Kindle のハイライトをいちいち Scrapbox にコピーするのも大変
Kindle を使って本を読んでいる人は、使っていると思います。ハイライト機能。
Kindle でハイライトをするとAmazonの専用サイトでハイライトを見れるようになります。
こんな感じで
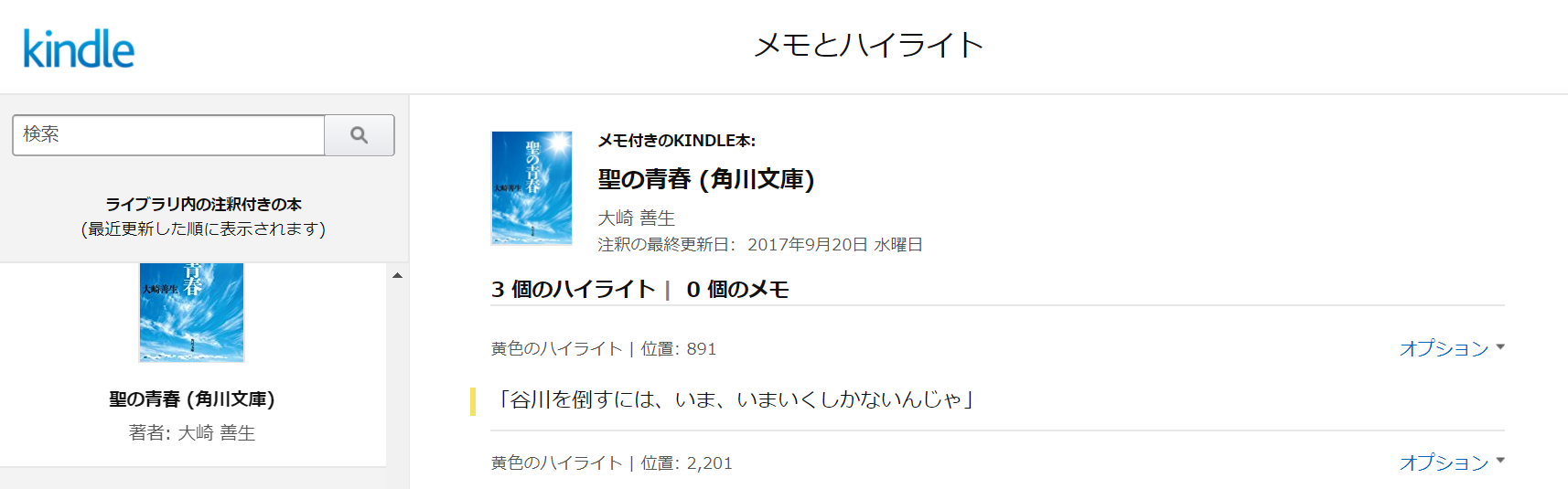
Kindleは基本電車で使っているので、そのときにはメモをしないで後でハイライトと一緒にいろいろ考えながらメモしています。でも、これをいちいちどっかにコピーするのも大変なのです。
なので自動でハイライトをいろいろ書き込めるメモにコピーしたいと思います。
メモは普段 Scrapbox 使っていています。
Amazonもscrapboxもログインが必要なものなので、色々いじるために selenium を使用します。
作成したコードはgithubにあげています。
getKindleHighLight.py は更新されたハイライトを取得し、ファイルに保存するファイルです。
pushscrbbyhlesschrome.py は上記ファイルによって新たに更新されたと保存されたハイライトをスクボにアップするファイルです。
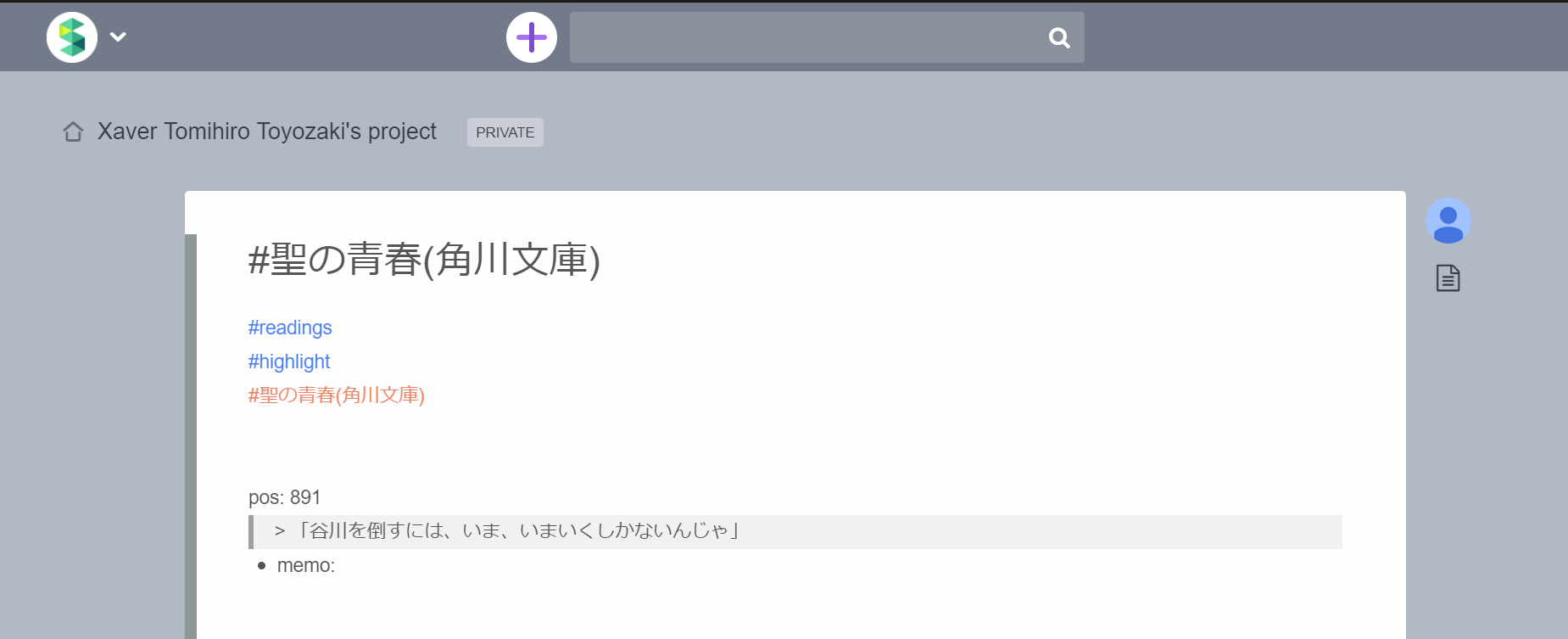
最終的に、自動でアップされたハイライトはこのようにscrapboxに記述されるようにしました。
selenium で phantomjs と headless chromeを使う。
selenium はブラウザをコードから操作するものです。
操作するブラウザに合わせて別途webdriverが必要だったりします。
ここらへんはそれぞれググれば出てきます。
そして、結論からいうと今回の目的を果たすためにはこの2つのブラウザをわざわざ使う必要があります。
PhantomJS
phantomjs はwebkitベースのヘッドレスブラウザとして使われています。
しかし、後述するchromeがheadlessモード(GUI無し)を搭載したことで、昨年をもって開発が終了しています。
今回重要なのは、phantomjsではamazonはログインできるけど、google認証は超えられないということです。
理由はよくはわかりませんが、メールアドレスを入れたあとにnextを押しても先にすすまないです。
半年ほど前であればできたそうですがここ数ヶ月でできなくなったようで、海外の質問サイトをみても同様の状態でした。
scrapboxはログインするときgoogle認証を必要とするので、phantomjsでは入れません。
しかもamazonはphantomjsだと1時間に5回以上ログインすると、画像認証が必要なログイン画面に飛ばされておそらくログインできません。
※厳密にはログインできるかもしれません。画像認証にはとてもかんたんな画像だったのでOCRで突破しようとしたら少しだけ難しい画像に置き換わってまたログイン画面に飛ばされました。予想ですが、それをとっぱしてもどんどん難しい画像が出てくるだけだと思います。しかも、その時のURLを普通の状態のブラウザで開いても存在しないといわれます。
なので、頻繁にログインはできませんが、kindleのハイライトを取得するためにphantomjsを使います。
こんな感じでAmazonにログインします。
UserAgent = "Safari/537.36 Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66"
driver = webdriver.PhantomJS(
desired_capabilities={'phantomjs.page.settings.userAgent': UserAgent,
},
)
driver.set_window_size(1920, 1080)
print('drive start')
url = 'read.amazon.co.jp/notebook'
driver.get(url)
sleep(3)
uid = driver.find_element_by_id('ap_email')
upw = driver.find_element_by_id('ap_password')
uid.send_keys(USER)
upw.send_keys(PASS)
sleep(5)
driver.find_element_by_id('signInSubmit').click()
sleep(5)
headless Chrome
正しくはchrome のheadless バージョンをselenium で扱えるようになったということです。
headless chromeはchrome59以降に搭載されているのでちゃんと更新してる人であれば、すでに対応してる人が多いと思います。
しかし、Macではデフォルトのchromeではなぜかうまくいかなかったので、chrome canaryを使ってください。開発者用chrome的なものらしいですね。
ちなみにlinuxだと普通のchromeでheadlessで実行できました。
そしてまたもや重要なのは、chrome のheadlessモードで実行するとamazonにログインできないのです。
さきほどphantomjsであれば1時間に4回はログインできると書きましたが、chromeのheadlessモードだと一回も入れてくれません。
逆にchromeなだけあって(?)google認証でもログインできます。
これでスクボを直接書き換えます。
ちなみにchrome headlessでスクボにログインするのはこんな感じです。
USER = 'mail'
PASS = 'pass'
options = Options()
options.binary_location = '/Applications/Google Chrome Canary.app/Contents/MacOS/Google Chrome Canary'
options.add_argument('--headless')
options.add_argument('--disable-gpu')
driver = webdriver.Chrome(chrome_options=options)
url = 'https://scrapbox.io/xavermemo/'
driver.get(url)
sleep(4)
# login with google page
btn = driver.find_element_by_class_name('btn')
actions = ActionChains(driver)
actions.move_to_element(btn)
actions.click()
actions.perform()
sleep(5)
# mail address
actions.reset_actions()
uid = driver.find_element_by_id('identifierId')
actions.move_to_element(uid)
actions.click()
actions.send_keys()
actions.send_keys(Keys.RETURN)
actions.perform()
急にactionChainを使い始めたのは単純のその後にも大量にwebdriverを使う必要があったので、機能ごとに見やすいようにするためだけです。
おわりに
ということで、amazonそしてgoogleという巨大プラットフォームにログインするために知見でした。
細かいコードはgithubを見てください。
とくに難しいことはしていないですが、なぜかよくわからないけどできないが重なる地味に大変なものになってしまいました。